There’s a new hot trend in AI: text-to-image generators. Feed these programs any text you like and they’ll generate remarkably accurate pictures that match that description. They can match a range of styles, from oil paintings to CGI renders and even photographs, and — though it sounds cliched — in many ways the only limit is your imagination.
To date, the leader in the field has been DALL-E, a program created by commercial AI lab OpenAI (and updated just back in April). Yesterday, though, Google announced its own take on the genre, Imagen, and it just unseated DALL-E in the quality of its output.
The best way to understand the amazing capability of these models is to simply look over some of the images they can generate. There’s some generated by Imagen above, and even more below (you can see more examples at Google’s dedicated landing page).
In each case, the text at the bottom of the image was the prompt fed into the program, and the picture above, the output. Just to stress: that’s all it takes. You type what you want to see and the program generates it. Pretty fantastic, right?
But while these pictures are undeniably impressive in their coherence and accuracy, they should also be taken with a pinch of salt. When research teams like Google Brain release a new AI model they tend to cherry-pick the best results. So, while these pictures all look perfectly polished, they may not represent the average output of the Image system.
Often, images generated by text-to-image models look unfinished, smeared, or blurry — problems we’ve seen with pictures generated by OpenAI’s DALL-E program. (For more on the trouble spots for text-to-image systems, check out this interesting Twitter thread that dives into problems with DALL-E. It highlights, among other things, the tendency of the system to misunderstand prompts, and struggle with both text and faces.)
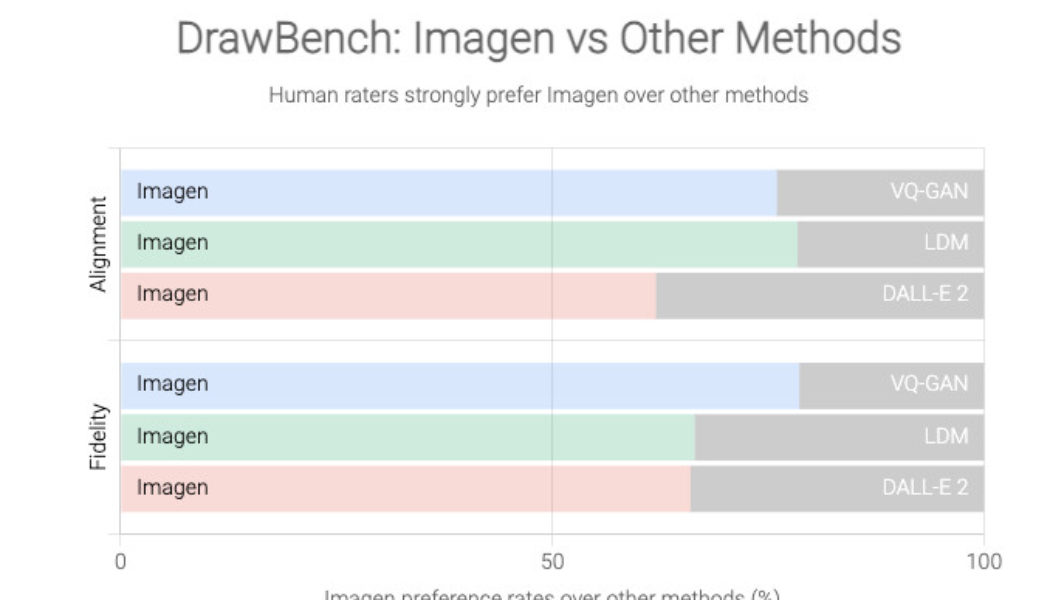
Google, though, claims that Imagen produces consistently better images than DALL-E 2, based on a new benchmark it created for this project named DrawBench.
DrawBench isn’t a particularly complex metric: it’s essentially a list of some 200 text prompts that Google’s team fed into Imagen and other text-to-image generators, with the output from each program then judged by human raters. As shown in the graphs below, Google found that humans generally preferred the output from Imagen to that of rivals’.
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/23584875/Screenshot_2022_05_24_at_11.00.33.png)
It’ll be hard to judge this for ourselves, though, as Google isn’t making the Imagen model available to the public. There’s good reason for this, too. Although text-to-image models certainly have fantastic creative potential, they also have a range of troubling applications. Imagine a system that generates pretty much any image you like being used for fake news, hoaxes, or harassment, for example. As Google notes, these systems also encode social biases, and their output is often racist, sexist, or toxic in some other inventive fashion.
A lot of this is due to how these systems are programmed. Essentially, they’re trained on huge amounts of data (in this case: lots of pairs of images and captions) which they study for patterns and learn to replicate. But these models need a hell of a lot of data, and most researchers — even those working for well-funded tech giants like Google — have decided that it’s too onerous to comprehensively filter this input. So, they scrape huge quantities of data from the web, and as a consequence their models ingest (and learn to replicate) all the hateful bile you’d expect to find online.
As Google’s researchers summarize this problem in their paper: “[T]he large scale data requirements of text-to-image models […] have have led researchers to rely heavily on large, mostly uncurated, web-scraped dataset […] Dataset audits have revealed these datasets tend to reflect social stereotypes, oppressive viewpoints, and derogatory, or otherwise harmful, associations to marginalized identity groups.”
In other words, the well-worn adage of computer scientists still applies in the whizzy world of AI: garbage in, garbage out.
Google doesn’t go into too much detail about the troubling content generated by Imagen, but notes that the model “encodes several social biases and stereotypes, including an overall bias towards generating images of people with lighter skin tones and a tendency for images portraying different professions to align with Western gender stereotypes.”
This is something researchers have also found while evaluating DALL-E. Ask DALL-E to generate images of a “flight attendant,” for example, and almost all the subjects will be women. Ask for pictures of a “CEO,” and, surprise, surprise, you get a bunch of white men.
For this reason OpenAI also decided not release DALL-E publicly, but the company does give access to select beta testers. It also filters certain text inputs in an attempt to stop the model being used to generate racist, violent, or pornographic imagery. These measures go some way to restricting potential harmful applications of this technology, but the history of AI tells us that such text-to-image models will almost certainly become public at some point in the future, with all the troubling implications that wider access brings.
Google’s own conclusion is that Imagen “is not suitable for public use at this time,” and the company says it plans to develop a new way to benchmark “social and cultural bias in future work” and test future iterations. For now, though, we’ll have to be satisfied with the company’s upbeat selection of images — raccoon royalty and cacti wearing sunglasses. That’s just the tip of the iceberg, though. The iceberg made from the unintended consequences of technological research, if Imagen wants to have a go at generating that.








