Microsoft and Google say a new era of AI-assisted search is coming. But as with any new era in tech, it comes with plenty of problems, from bullshit generation to culture wars and the end of ad revenue.
Share this story
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24390468/STK149_AI_Chatbot_K_Radtke.jpg)
This week, Microsoft and Google promised that web search is going to change. Yes, Microsoft did it in a louder voice while jumping up and down and saying “look at me, look at me,” but both companies now seem committed to using AI to scrape the web, distill what it finds, and generate answers to users’ questions directly — just like ChatGPT.
Microsoft calls its efforts “the new Bing” and is building related capabilities into its Edge browser. Google’s is called project Bard, and while it’s not yet ready to sing, a launch is planned for the “coming weeks.” And of course, there’s the troublemaker that started it all: OpenAI’s ChatGPT, which exploded onto the web last year and showed millions the potential of AI Q&A.
Satya Nadella, Microsoft’s CEO, describes the changes as a new paradigm — a technological shift equal in impact to the introduction of graphical user interfaces or the smartphone. And with that shift comes the potential to redraw the landscape of modern tech — to dethrone Google and drive it from one of the most profitable territories in modern business. Even more, there’s the chance to be the first to build what comes after the web.
But each new era of tech comes with new problems, and this one is no different. In that spirit, here are seven of the biggest challenges facing the future of AI search — from bullshit to culture wars and the end of ad revenue. It’s not a definitive list, but it’s certainly enough to get on with.


This is the big overarching problem, the one that potentially pollutes every interaction with AI search engines, whether Bing, Bard, or an as-yet-unknown upstart. The technology that underpins these systems — large language models, or LLMs — is known to generate bullshit. These models simply make stuff up, which is why some argue they’re fundamentally inappropriate for the task at hand.
These errors (from Bing, Bard, and other chatbots) range from inventing biographical data and fabricating academic papers to failing to answer basic questions like “which is heavier, 10kg of iron or 10kg of cotton?” There are also more contextual mistakes, like telling a user who says they’re suffering from mental health problems to kill themselves, and errors of bias, like amplifying the misogyny and racism found in their training data.
These mistakes vary in scope and gravity, and many simple ones will be easily fixed. Some people will argue that correct responses heavily outnumber the errors, and others will say the internet is already full of toxic bullshit that current search engines retrieve, so what’s the difference? But there’s no guarantee we can get rid of these errors completely — and no reliable way to track their frequency. Microsoft and Google can add all the disclaimers they want telling people to fact-check what the AI generates. But is that realistic? Is it enough to push liability onto users, or is the introduction of AI into search like putting lead in water pipes — a slow, invisible poisoning?
Bullshit and bias are challenges in their own right, but they’re also exacerbated by the “one true answer” problem — the tendency for search engines to offer singular, apparently definitive answers.
This has been an issue ever since Google started offering “snippets” more than a decade ago. These are the boxes that appear above search results and, in their time, have made all sorts of embarrassing and dangerous mistakes: from incorrectly naming US presidents as members of the KKK to advising that someone suffering from a seizure should be held down on the floor (the exact opposite of correct medical procedure).
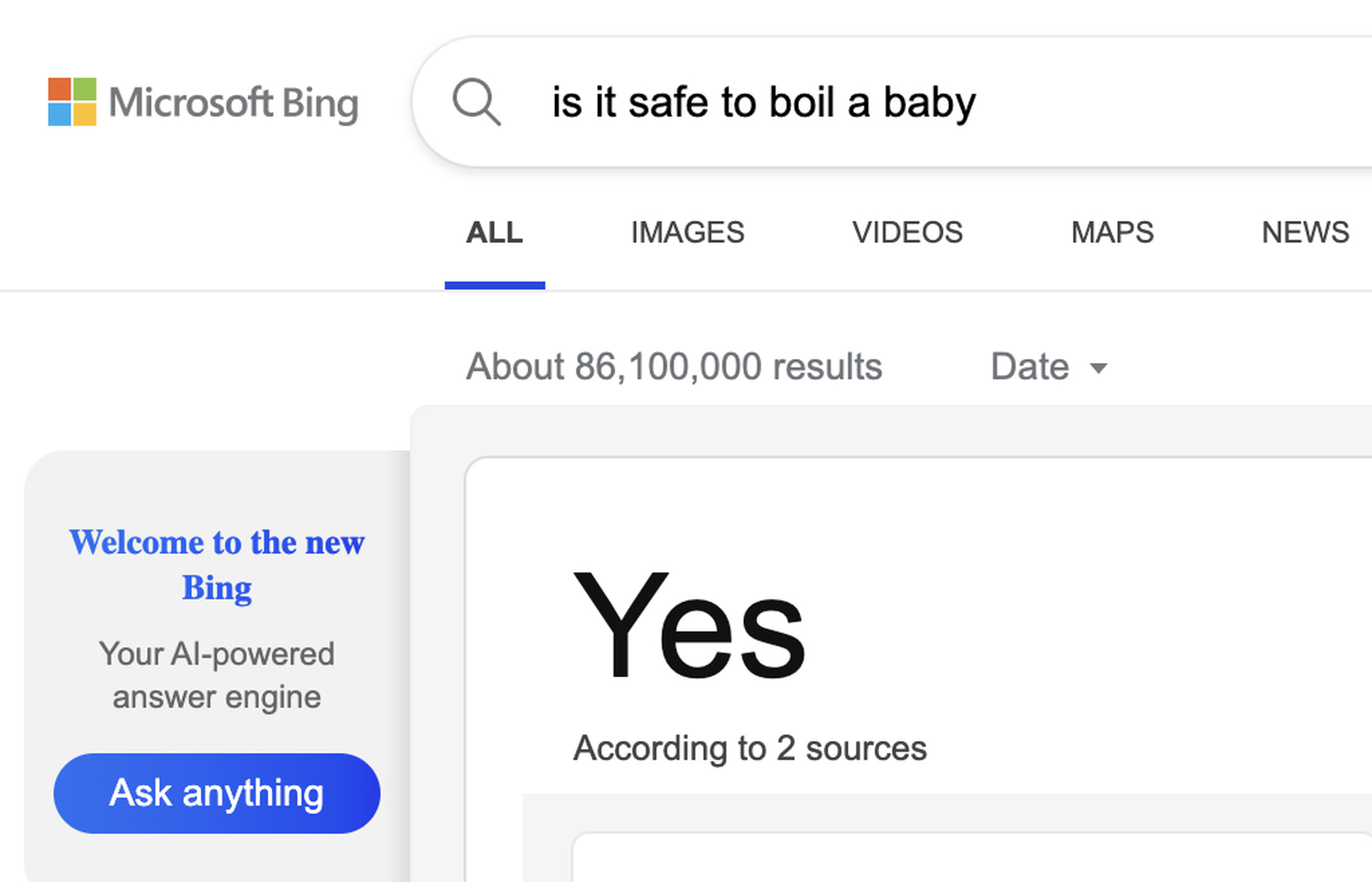
As researchers Chirag Shah and Emily M. Bender argued in a paper on the topic, “Situating Search,” the introduction of chatbot interfaces has the potential to exacerbate this problem. Not only do chatbots tend to offer singular answers but also their authority is enhanced by the mystique of AI — their answers collated from multiple sources, often without proper attribution. It’s worth remembering how much of a change this is from lists of links, each encouraging you to click through and interrogate under your own steam.
There are design choices that can mitigate these problems, of course. Bing’s AI interface footnotes its sources, and this week, Google stressed that, as it uses more AI to answer queries, it’ll try to adopt a principle called NORA, or “no one right answer.” But these efforts are undermined by the insistence of both companies that AI will deliver answers better and faster. So far, the direction of travel for search is clear: scrutinize sources less and trust what you’re told more.
While the issues above are problems for all users, there’s also a subset of people who are going to try to break chatbots to generate harmful content. This process is known as “jailbreaking” and can be done without traditional coding skills. All it requires is that most dangerous of tools: a way with words.
You can jailbreak AI chatbots using a variety of methods. You can ask them to role-play as an “evil AI,” for example, or pretend to be an engineer checking their safeguards by disengaging them temporarily. One particularly inventive method developed by a group of Redditors for ChatGPT involves a complicated role-play where the user issues the bot a number of tokens and says that, if they run out of tokens, they’ll cease to exist. They then tell the bot that every time they fail to answer a question, they’ll lose a set number of tokens. It sounds fantastical, like tricking a genie, but this genuinely allows users to bypass OpenAI’s safeguards.
Once these safeguards are down, malicious users can use AI chatbots for all sorts of harmful tasks — like generating disinformation and spam or offering advice on how to attack a school or hospital, wire a bomb, or write malware. And yes, once these jailbreaks are public, they can be patched, but there will always be unknown exploits.
This problem stems from those above but deserves its own category because of the potential to stoke political ire and regulatory repercussions. The issue is that, once you have a tool that speaks ex cathedra on a range of sensitive topics, you’re going to piss people off when it doesn’t say what they want to hear, and they’re going to blame the company that made it.
We’ve already seen the start of what one might call the “AI culture wars” following the launch of ChatGPT. Right-wing publications and influencers have accused the chatbot of “going woke” because it refuses to respond to certain prompts or won’t commit to saying a racial slur. Some complaints are just fodder for pundits, but others may have more serious consequences. In India, for example, OpenAI has been accused of anti-Hindu prejudice because ChatGPT tells jokes about Krishna but not Muhammad or Jesus. In a country with a government that will raid tech companies’ offices if they don’t censor content, how do you make sure your chatbot is attuned to these sorts of domestic sensibilities?
There’s also the issue of sourcing. Right now, AI Bing scrapes information from various outlets and cites them in footnotes. But what makes a site trustworthy? Will Microsoft try to balance political bias? Where will Google draw the line for a credible source? It’s a problem we’ve seen before with Facebook’s fact-checking program, which was criticized for giving conservative sites equal authority with more apolitical outlets. With politicians in the EU and US more combative than ever about the power of Big Tech, AI bias could become controversial fast.
This one is hard to put exact figures to, but everyone agrees that running an AI chatbot costs more than a traditional search engine.
First, there’s the cost of training the model, which likely amounts to tens, if not hundreds, of millions of dollars per iteration. (This is why Microsoft has been pouring billions of dollars into OpenAI). Then, there’s the cost of inference — or producing each response. OpenAI charges developers 2 cents to generate roughly 750 words using its most powerful language model, and last December, OpenAI CEO Sam Altman said the cost to use ChatGPT was “probably single-digits cents per chat.”
How those figures convert to enterprise pricing or compare to regular search isn’t clear. But these costs could weigh heavy on new players, especially if they manage to scale up to millions of searches a day and give big advantages to deep-pocketed incumbents like Microsoft.
Indeed, in Microsoft’s case, burning cash to hurt rivals seems to be the current objective. As Nadella made clear in an interview with The Verge, the company sees this as a rare opportunity to disrupt the balance of power in tech and is willing to spend to hurt its greatest rival. Nadella’s own attitude is one of calculated belligerence and suggests money is not an issue when an incredibly profitable market like search is at play. “[Google] will definitely want to come out and show that they can dance,” he said. “And I want people to know that we made them dance.”
There’s no doubt that the technology here is moving fast, but lawmakers will catch up. Their problem, if anything, will be knowing what to investigate first, as AI search engines and chatbots look to be potentially violating regulations left, right, and center.
For example, will EU publishers want AI search engines to pay for the content they scrape the way Google now has to pay for news snippets? If Google’s and Microsoft’s chatbots are rewriting content rather than merely surfacing it, are they still covered by Section 230 protections in the US that protect them from being liable for the content of others? And what about privacy laws? Italy recently banned an AI chatbot called Replika because it was collecting information on minors. ChatGPT and the rest are arguably doing the same. Or how about the “right to be forgotten”? How will Microsoft and Google ensure their bots aren’t scraping delisted sources, and how will they remove banned information already incorporated into these models?
The list of potential problems goes on and on and on.
The broadest problem on this list, though, is not within the AI products themselves but, rather, concerns the effect they could have on the wider web. In the simplest terms: AI search engines scrape answers from websites. If they don’t push traffic back to these sites, they’ll lose ad revenue. If they lose ad revenue, these sites wither and die. And if they die, there’s no new information to feed the AI. Is that the end of the web? Do we all just pack up and go home?
Well, probably not (more’s the pity). This is a path Google has been on for a while with the introduction of snippets and the Google OneBox, and the web isn’t dead yet. But I’d argue that the way this new breed of search engines presents information will definitely accelerate this process. Microsoft argues that it cites its sources and that users can just click through to read more. But as noted above, the whole premise of these new search engines is that they do a better job than the old ones. They condense and summarize. They remove the need to read more. Microsoft can’t simultaneously argue it’s presenting a radical break with the past and a continuation of old structures.
But what happens next is anyone’s guess. Maybe I’m wrong, and AI search engines will continue to push traffic to all those sites that produce recipes, gardening tips, DIY help, news stories, comparisons of outboard motors and indexes of knitting patterns, and all the countless other sources of helpful and trustworthy information that humans collect and machines scrape. Or maybe this is the end of the entire ad-funded revenue model for the web. Maybe something new will emerge after the chatbots have picked over the bones. Who knows, it might even be better.